






Authors:
Raj Kumar Thadem, Bharat Varla, Srinivasan Purushothaman
Abstract:
This Disclosure proposes a system and method for orchestrating containerized workloads across heterogeneous Kubernetes environments spanning public cloud clusters, private cloud clusters, and resource-constrained edge distributions. Lightweight cluster agents collect real-time telemetry streamed to a federated aggregator that normalizes metrics and annotates each with locality metadata. A machine-learning decision engine — comprising time-series forecasting models, anomaly detection, and a reinforcement-learning placement policy network — generates demand forecasts and ranked candidate placement actions. A multi-objective constraint solver filters candidates against operator-defined constraints, including data residency, latency SLOs, cost ceilings, edge thermal and power budgets, and WAN bandwidth caps, emitting a Pareto-optimal placement plan. A workload balancer executes the plan using Kubernetes-native primitives or presents it for operator approval. A unified dashboard and capacity planner provide fleet-wide visibility and long-horizon scaling guidance, eliminating cluster hot spots before they form.
Background:
Modern enterprises operate containerized workloads across multiple Kubernetes distributions, including public cloud managed services, private or on-premises deployments, and increasingly at the edge via lightweight distributions deployed on retail store floors, factory equipment, and telecommunications multi-access edge compute (MEC) nodes.
Problem Solved by this Proposal:
No existing system provides a unified, closed-loop, predictive orchestration control plane that jointly optimizes workload placement across cloud and edge Kubernetes clusters while respecting edge-specific physical constraints (thermal budget, power budget, WAN bandwidth cap) and preserving data residency requirements.
Known Solutions and Their Drawbacks:
|
Solution |
Drawback |
|
Kubernetes HPA / VPA / Cluster Autoscaler |
Operate entirely within a single cluster. Cannot redistribute load to underutilized neighboring clusters, cannot anticipate demand spikes before they cause resource saturation, and have no awareness of edge-specific physical constraints such as thermal limits and power budgets. |
|
Multi-cluster federation tools |
Provide mechanisms for propagating Kubernetes resources across clusters but require hand-authored placement policies. No machine-learning-based demand forecasting, no multi-objective constraint solving, and no dynamic policy adjustment based on observed cluster state. |
|
Edge orchestration systems |
Address deployment of containerized workloads to edge nodes but do not integrate with cloud-cluster orchestrators under a unified predictive policy engine. Cloud orchestrators have no visibility into edge-site metrics, thermal conditions, or bandwidth constraints. |
|
Connectivity / traffic-routing tools |
Provide traffic routing only; no workload placement, forecasting, or constraint solving. |
|
Observability platforms |
Provide alerting on resource saturation but do not generate closed-loop, autonomous placement recommendations or execute remediations. |
|
AI advisory tools |
Surface issue identification without tying insights to constraint-satisfying, immediately-executable placement actions. |
|
Multi-cluster lifecycle / policy tools |
Rule-driven placement only; no ML-driven forecasting or joint cloud+edge optimization. |
No prior art system, alone or in obvious combination, provides a closed-loop, predictive, edge- and locality-aware orchestration system that jointly optimizes cost, latency, data residency, and edge-specific physical constraints across heterogeneous Kubernetes distributions. There is a need in the art for such a system.
Description:
Overview: The ClusterSync Optimizer
The ClusterSync Optimizer is an AI-driven control plane that operates as a layer above existing Kubernetes clusters. It collects real-time telemetry from all managed clusters (cloud and edge), feeds it through an ML-driven decision engine, applies multi-objective constraint solving, and executes or recommends placement actions — all in a closed loop.
I. Cluster Agent (Element 100)
Each managed cluster hosts at least one cluster agent (100), preferably deployed as a Kubernetes DaemonSet or Deployment, designed to a resource budget of less than 50 MB of RAM and less than 0.1 virtual CPU at idle. This enables deployment on resource-constrained edge distributions including K3s and MicroK8s. The agent collects resource utilization metrics (CPU, memory, I/O, network, GPU), scheduling latency, and application-level Service Level Indicators (SLIs) by querying the Kubernetes API Server and Metrics Server.
In edge deployments where WAN connectivity is intermittent, the agent operates a store-and-forward telemetry buffer (100a) that accumulates metrics locally using delta compression to reduce storage overhead, and transmits buffered data to the federated aggregator upon connectivity restoration. The agent uses adaptive sampling to reduce telemetry volume during bandwidth-constrained periods, with a default collection cycle of five minutes for edge clusters versus thirty seconds for cloud clusters.
II. Federated Telemetry Aggregator (Element 200)
The federated telemetry aggregator (200) receives telemetry streams from all cluster agents and performs normalization across heterogeneous Kubernetes distributions. Normalization translates distribution-specific metric schemas into a canonical format. Each normalized metric record is annotated with locality metadata comprising: cloud provider identifier; geographic region; availability zone; edge-site identifier; and regulatory residency-zone designation.
“Locality metadata” as used herein means machine-readable labels that identify the geographic, jurisdictional, and topological origin of a metric and that are preserved through all downstream processing stages.
The aggregator supports Prometheus-compatible scraping and OpenTelemetry ingestion pipelines, and normalizes telemetry received from agents deployed in clusters running at least two of the available Kubernetes distributions.
III. Machine-Learning Decision Engine (Element 300)
The ML decision engine (300) receives annotated telemetry from the aggregator and produces: (i) demand forecasts for each managed cluster, and (ii) a ranked set of candidate placement actions. The engine comprises an ensemble of time-series forecasting models including at least one of: Facebook Prophet, Long Short-Term Memory (LSTM) neural networks, and Temporal Fusion Transformer (TFT). Per-tenant fine-tuning on historical telemetry is supported.
The engine further comprises a reinforcement-learning (RL) placement policy network that is continuously updated based on observed placement outcomes. The RL network receives a reward signal derived from at least one of: realized latency delta following each executed placement; cost variance between forecast and actual resource expenditure; and SLO violation rate in the period following placement execution. Anomaly detection is performed using gradient-boosted classifiers operating on the normalized telemetry stream.
In a federated-learning mode of operation, model gradient updates are computed locally within each cluster’s agent and transmitted to a central aggregation server, where they are combined using a federated averaging algorithm (such as those implemented in Flower or TensorFlow Federated) without exporting raw telemetry data. This mode is provided for deployment environments subject to regulatory data-residency requirements, including healthcare (HIPAA), financial services, and regulated retail operations.
III(a). Bootstrap Mode and Cold-Start Handling
To address the cold-start condition that arises on initial deployment when the reinforcement-learning placement policy network has no prior placement history from which to derive a reward signal, the ML decision engine operates in a bootstrap mode during which a rule-based heuristic policy, derived from static resource utilization thresholds and operator-defined affinity preferences, governs placement decisions in place of the RL network. The decision engine transitions automatically from bootstrap mode to RL-driven mode once a configurable minimum observation window has been satisfied, defined as a minimum number of completed placement cycles with measurable post-placement outcome telemetry.
To accelerate convergence on new deployments, the system supports loading a pre-trained base policy checkpoint, generated offline from historical telemetry of similar cluster topologies or from a simulator environment, which is then fine-tuned online as live placement outcomes are observed. This warm-start capability reduces the bootstrap period from days to hours in typical fleet configurations. The RL network’s confidence score is surfaced on the unified dashboard (Element 600) so that operators can observe the transition from heuristic to learned policy and intervene if the confidence score fails to converge within an expected window.
IV. Policy and Constraint Solver (Element 400)
The policy and constraint solver (400) receives the ranked candidate placement actions from the ML decision engine and filters them against a set of declarative, operator-defined constraints to produce a placement plan. The solver employs multi-objective Integer Linear Programming (ILP) augmented by heuristics to produce a result within operationally acceptable latency bounds.
The solver supports at least five categories of hard and soft constraints:
- Data residency and GDPR/regulatory jurisdiction constraints
- End-user latency SLO requirements
- Monetary cost ceilings
- Affinity and anti-affinity rules
- Edge-specific physical constraints comprising edge thermal budget, edge power budget, and WAN bandwidth cap (a novel constraint type not present in prior art multi-cluster schedulers)
The solver emits a placement plan that satisfies all hard constraints and is Pareto-optimal with respect to operator-configured objective weights across the soft constraint dimensions. It always emits a feasible plan; it does not emit a plan that violates any hard constraint. Operator-tunable trade-off weights are configurable per objective and per tenant.
V. Workload Balancer and Migration Executor (Element 500)
The workload balancer (500) receives the placement plan and either executes it autonomously (autonomous mode) or presents it to a human operator for approval (advisory mode). Execution is performed exclusively using Kubernetes-native primitives, requiring no custom infrastructure modifications by the adopting enterprise. Primitives used include: scaling of Kubernetes Deployments; adjustment of NodeAffinity and PodAffinity rules; draining of nodes; federation propagation via Karmada or KubeFed APIs; and stateful workload migration via CSI volume snapshot and restore operations.
VI. Unified Dashboard and Capacity Planner (Element 600)
The unified dashboard (600) provides a single-pane-of-glass view across all managed clusters and edge sites, supporting drill-down from fleet level to cluster, node, and workload level. The dashboard presents active alerts, AI-generated recommendations, and historical trend analysis. The co-located capacity planner uses long-horizon demand forecasts to recommend cluster scale-up actions, new edge-site provisioning, and cost-optimization actions including Reserved Instance and Savings Plan purchases.
VII. Operational Data Flow (FIG. 2)
The end-to-end data flow proceeds through five stages:
- Telemetry Collection: Agents stream CPU/Mem/Net/GPU metrics from each cluster
- Normalize & Annotate: Aggregator tags each metric with cloud/region/AZ/edge-site locality metadata
- AI Forecast & Rank: ML engine runs Prophet+LSTM+TFT ensemble and RL policy network to produce ranked candidate actions
- Constraint Solve: ILP solver filters candidates to a Pareto-optimal placement plan that is feasible vs. all hard constraints
- Execute / Advise: Workload balancer applies Kubernetes-native primitives or presents plan for operator approval
Non-Obviousness
The novelty of the present invention lies in the combination of: (1) fleet-level cross-cluster workload redistribution; (2) ensemble ML demand forecasting per tenant; (3) multi-objective constraint solving incorporating edge-specific physical constraints including thermal budget, power budget, and WAN bandwidth cap; and (4) a federated-learning telemetry privacy mode — integrated into a single control-plane architecture. None of the prior art systems identified above, alone or in obvious combination, provides this integrated capability. The combination is non-obvious because the skilled artisan would not have been motivated to combine edge-physical-constraint-aware scheduling with federated-learning telemetry privacy in a single ML-driven placement engine, as these capabilities have historically been addressed by entirely separate product categories.
FIG. 1 — System Architecture Block Diagram of the ClusterSync Optimizer
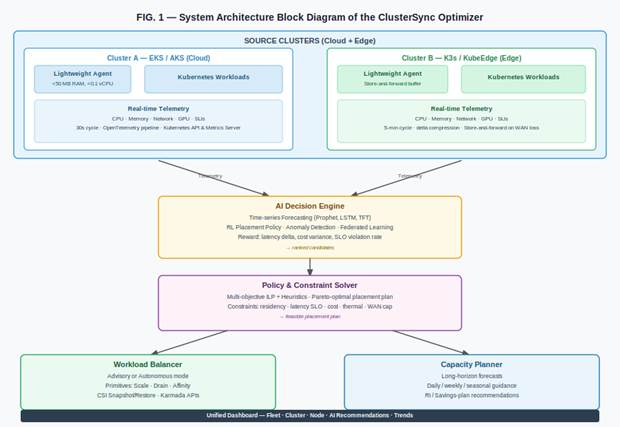
FIG. 1 — System Architecture Block Diagram of the ClusterSync Optimizer
Shows the source cluster layer (Cluster A: EKS/AKS cloud; Cluster B: K3s/KubeEdge edge), each with a Lightweight Agent (<50 MB RAM, <0.1 vCPU) and real-time telemetry pipelines feeding into the central AI Decision Engine (time-series forecasting, RL placement policy, anomaly detection, federated learning), which feeds into the Policy & Constraint Solver (multi-objective ILP + heuristics; constraints: residency, latency SLO, cost, thermal, WAN cap), which drives the Workload Balancer (advisory or autonomous mode; Kubernetes-native primitives: Scale, Drain, Affinity, CSI Snapshot/Restore, Karmada APIs) and Capacity Planner (long-horizon forecasts; RI/savings-plan recommendations), with a Unified Dashboard below (Fleet · Cluster · Node · AI Recommendations · Trends).
FIG. 2 — Operational Data Flow: Telemetry to Placement Execution
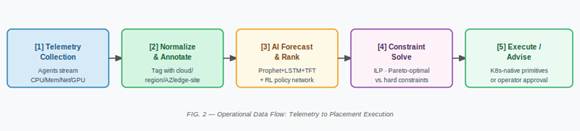
FIG. 2 — Operational Data Flow: Telemetry to Placement Execution
Five-stage pipeline: [1] Telemetry Collection (Agents stream CPU/Mem/Net/GPU) → [2] Normalize & Annotate (Tag with cloud/region/AZ/edge-site) → [3] AI Forecast & Rank (Prophet+LSTM+TFT / RL policy network) → [4] Constraint Solve (ILP · Pareto-optimal vs. hard constraints) → [5] Execute / Advise (Kubernetes-native primitives or operator approval).
FIG. 3 — Key Architectural Properties
|
Property |
Description |
Mechanism |
|
Predictive |
Anticipates demand before bottlenecks occur |
Prophet, LSTM, TFT ensemble forecasting |
|
Constraint-aware |
Plans are feasible against hard constraints and Pareto-optimal against operator-configured objective weights |
Multi-objective ILP + heuristics |
|
Locality-aware |
Accounts for data gravity, residency, and user proximity |
Locality metadata tagging per metric (cloud/region/AZ/edge-site) |
|
Distribution-agnostic |
One control plane for every Kubernetes distribution, cloud to edge |
Normalized telemetry aggregation layer |
|
Edge-resilient |
Participates in orchestration despite intermittent WAN connectivity |
Store-and-forward buffer, delta compression, adaptive sampling |
|
Privacy-preserving |
Raw telemetry never leaves regulated sites |
Federated learning: gradient-only aggregation (Flower / TF Federated) |
Usages
|
Use Case |
Description |
|
Retail edge |
Orchestrate containerized point-of-sale and inventory workloads across store-floor K3s nodes and central cloud clusters, respecting edge thermal and power budgets during peak hours and redistributing load to cloud when edge capacity is saturated. |
|
Telecommunications MEC |
Place latency-sensitive 5G application workloads on the nearest MEC node while respecting WAN bandwidth caps and automatically migrating workloads if MEC capacity is predicted to be exhausted. |
|
Healthcare / regulated industries |
Use federated-learning mode to improve placement models across hospital-site Kubernetes clusters without exporting patient data outside each facility’s HIPAA-regulated boundary. |
|
Financial services |
Enforce data-residency constraints (GDPR, regional regulations) while optimizing cost and latency across multi-region cloud clusters. |
|
Factory / industrial IoT |
Deploy on factory-floor MicroK8s nodes alongside cloud EKS clusters; maintain orchestration continuity during WAN outages via store-and-forward buffer; optimize across edge thermal and power constraints unique to manufacturing environments. |
|
Multi-tenant SaaS providers |
Per-tenant ML fine-tuning and per-tenant operator-configurable constraint weight tuning across shared infrastructure pools. |
Claims:
Claim 1 (System)
A system for orchestrating containerized workloads across a plurality of Kubernetes clusters, wherein at least one cluster is a cloud-managed cluster and at least one cluster is an edge-deployed cluster, comprising: a plurality of cluster agents each configured to collect real-time telemetry comprising resource utilization metrics, scheduling latency measurements, and application service-level indicators; a federated telemetry aggregator configured to normalize the telemetry across heterogeneous Kubernetes distributions and annotate each metric with locality metadata comprising cloud provider identifier, geographic region, availability zone, and edge-site identifier; a machine-learning decision engine configured to generate (i) demand forecasts for each managed cluster, and (ii) a ranked set of candidate placement actions; a policy and constraint solver configured to filter candidate placement actions against declarative operator-defined constraints including at least one edge-specific constraint selected from edge thermal budget, edge power budget, and WAN bandwidth cap, to produce a Pareto-optimal placement plan that satisfies all hard constraints; and a workload balancer configured to execute the placement plan by applying Kubernetes-native primitives comprising deployment scaling, node affinity adjustments, node draining, and federation propagation APIs.
Claim 2
The system of claim 1, wherein the cluster agent deployed within the edge-deployed cluster comprises a store-and-forward telemetry buffer configured to accumulate metric records locally during periods of intermittent WAN connectivity and to transmit the accumulated records to the federated telemetry aggregator upon connectivity restoration.
Claim 3
The system of claim 1, wherein the policy and constraint solver performs multi-objective optimization over at least two objectives selected from: monetary cost of execution, end-user request latency, regulatory data residency jurisdiction, edge thermal and power budget consumption, and inter-cluster WAN bandwidth consumption.
Claim 4
The system of claim 1, wherein the machine-learning decision engine comprises an ensemble of time-series forecasting models and a reinforcement-learning placement policy network that is continuously updated based on observed placement outcomes, wherein the reinforcement-learning placement policy network receives a reward signal derived from at least one of: realized latency delta measured following each executed placement action; cost variance between forecast resource expenditure and actual resource expenditure; and SLO violation rate measured during the period following each executed placement action.
Claim 5
The system of claim 1, wherein the machine-learning decision engine operates in a federated-learning mode in which model gradient updates are computed locally within each managed cluster and aggregated centrally without exporting raw telemetry data outside the cluster in which the telemetry originated.
Claim 6
The system of claim 1, wherein the federated telemetry aggregator normalizes telemetry received from agents deployed in clusters running at least two of the available Kubernetes distributions.
Claim 7 (Method)
A computer-implemented method for reducing cluster resource saturation events across a heterogeneous Kubernetes fleet, comprising: collecting, by a plurality of cluster agents, real-time telemetry comprising resource utilization metrics and application service-level indicators; normalizing the telemetry across heterogeneous Kubernetes distributions and annotating each metric with locality metadata identifying at least cloud provider, region, availability zone, and edge-site; generating, by a machine-learning decision engine, demand forecasts for each cluster and a ranked set of candidate placement actions; solving, by a policy and constraint solver, a multi-objective optimization subject to declarative operator-defined constraints comprising at least one edge-specific physical constraint selected from edge thermal budget, edge power budget, and WAN bandwidth cap, to produce a placement plan that is feasible with respect to all hard constraints and Pareto-optimal with respect to operator-configured objective weights; and executing the placement plan via Kubernetes-native primitives, thereby redistributing containerized workloads across the fleet before cluster resource saturation occurs.
Claim 8
The method of claim 7, wherein at least one managed cluster is an edge cluster subject to intermittent WAN connectivity, and wherein collecting telemetry from the edge cluster comprises buffering metric records locally at the cluster agent using delta compression and transmitting the buffered records to a federated telemetry aggregator upon restoration of WAN connectivity.
Claim 9 (CRM — Aggregator)
A non-transitory computer-readable medium storing instructions that, when executed by one or more processors, implement a federated telemetry aggregator comprising: a normalization engine configured to receive telemetry from a plurality of cluster agents deployed in Kubernetes clusters running heterogeneous Kubernetes distributions and to translate distribution-specific metric schemas into a canonical metric format; and an annotation engine configured to attach to each canonical metric record a locality metadata record comprising cloud provider identifier, geographic region, availability zone, edge-site identifier, and regulatory residency-zone designation, wherein the locality metadata is preserved through all downstream processing stages.
Claim 10 (CRM — ML Engine)
A non-transitory computer-readable medium storing instructions that, when executed by one or more processors, implement a machine-learning decision engine configured to: receive annotated telemetry from a federated telemetry aggregator; generate, using an ensemble of time-series forecasting models comprising at least two of Prophet, LSTM, and Temporal Fusion Transformer, demand forecasts for each of a plurality of managed Kubernetes clusters; generate, using a reinforcement-learning placement policy network continuously updated via a reward signal derived from observed post-placement outcomes, a ranked set of candidate workload placement actions; and in a federated-learning mode, receive model gradient updates computed locally within each managed cluster and aggregate the updates centrally without accessing raw telemetry data.
Existing Art:
Existing Art Description
|
Karmada |
Multi-cluster resource federation, rule-based placement, no ML forecasting |
|
KubeFed / Open Cluster Management / Liqo |
Federation primitives, manual policy authoring |
|
KubeEdge / OpenYurt / Akri |
Edge-specific orchestration, not integrated with cloud under unified predictive policy engine |
|
Kubernetes HPA, VPA, Cluster Autoscaler |
Single-cluster scope, purely reactive autoscaling |
|
Istio multi-cluster, Submariner, Cilium Cluster Mesh |
Traffic routing only |
|
Rancher, Red Hat ACM, Google Anthos, Azure Arc, VMware Tanzu Mission Control |
Rule-driven placement, no ML |
|
Prometheus federation, Datadog, Dynatrace, New Relic |
Alerting and observability, no closed-loop autonomous placement |
|
K8sGPT, Kubernetes Resource Recommender (KRS) |
Advisory / issue surfacing, no closed-loop execution |
|
Flower, TensorFlow Federated |
Federated learning frameworks (enabling technology, not placement systems) |
|
Facebook Prophet, LSTM, TFT |
Time-series forecasting models (enabling technology) |
TGCS Reference 00780


