






Authors:
Sameet Sonaware
Abstract:
This project proposes a real-time monitoring solution that leverages overhead cameras in conjunction with Vision-Language Models (VLMs) or custom computer vision systems to detect and classify physical damage events. By fusing visual data with machine-generated logs, the system aims to identify anomalous behavior patterns and correlate them with specific damage incidents. The solution uniquely integrates multimodal data streams including video input, vibration sensors, device deformation metrics, baseline shape comparisons, and system logs to detect forceful or abnormal interactions with devices. By continuously monitoring these signals, it can flag misuse or potential damage before it disrupts operations. This multi-modal approach not only enhances loss prevention capabilities but also empowers retailers with actionable insights to improve store operations, employee training, and product durability. The system is scalable, privacy-conscious, and paves the way for proactive device maintenance in high-traffic retail settings, delivering operational benefits such as faster issue resolution, reduced downtime, and smarter design evolution through behavioral analytics.
Background:
Retail environments frequently face recurring maintenance issues, typically categorized as software malfunctions, hardware failures, or physical hardware damage. Physical damage often caused by improper or forceful handling by customers or employees can result in costly repairs, prolonged downtime, and reduced operational efficiency. Timely and proactive detection of such issues is critical to maintaining the system uptime and ensuring smooth store operations.
Current industry approaches primarily focus on post-incident diagnostics. These include:
- Thermal imaging, which detects abnormal heat signatures in electrical and mechanical systems [FLIR Systems] [Texada Software],
- Vibration pattern analysis, used to identify mechanical inconsistencies or early-stage component degradation [Mobius Institute],
- Pressure or stress monitoring, often employed in heavy equipment and industrial applications [Texada Software].
While effective in isolated industrial scenarios, these techniques are fundamentally reactive, identifying issues only after damage has already occurred. Additionally, they assume operation by trained personnel and lack the context of human-device interaction, which is critical in high-traffic retail environments where devices are frequently used by non-experts.
To address these limitations, we propose a real-time, multi-modal monitoring solution. Our system integrates visual input from existing loss prevention (LP) cameras with advanced Vision-Language Models (VLMs) and additional sensor data—including system event logs, vibration sensors, and device deformation metrics. This enables continuous surveillance of both device health and human interaction, allowing for real-time detection and classification of forceful or abnormal behavior that may lead to physical damage.
This proactive solution not only accelerates maintenance response time but also contributes to long-term improvements in product design. By identifying patterns of misuse and common failure points, manufacturers can redesign hardware for greater resilience and durability. Unlike traditional methods, this system emphasizes prevention over diagnosis and introduces a novel way of integrating human behavior analysis into device monitoring—an area not addressed in prior art or existing commercial solutions.
Description:
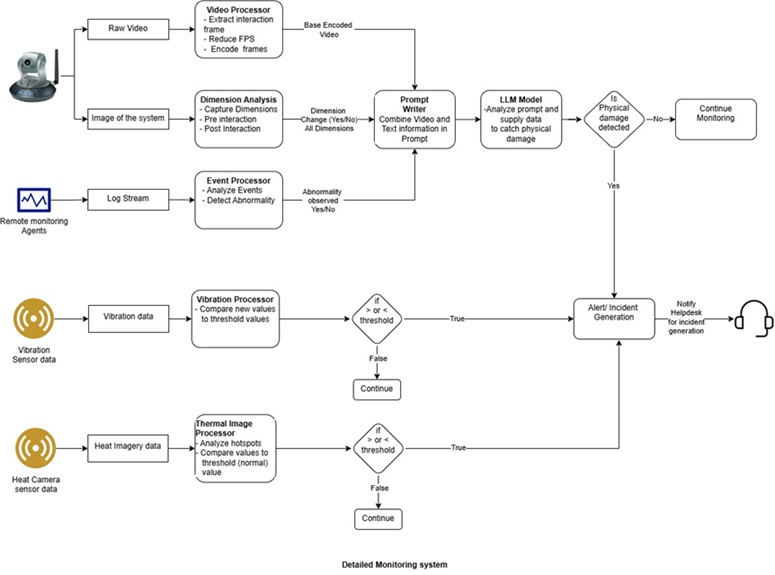
Below is a basic overview of the proposed system. A loss prevention camera continuously monitors the system and streams frames to a YOLOv3 object detection model. The model identifies whether a person is present in the frame. Detection of a person implies that an employee or customer is about to interact with the system. Upon detecting such interaction, the relevant frames are forwarded to a downstream model for further analysis to assess potential physical damage.
Citation
YOLOv3: Redmon, J., & Farhadi, A. (2018). YOLOv3: An Incremental Improvement. arXiv preprint arXiv:1804.02767. Retrieved from https://arxiv.org/abs/1804.02767

The invention aims to combine multi-modal data streams and pass them through either a Vision-Language Model (VLM) architecture or a custom computer vision-based trained model. Currently focusing on VLM approach.
Input Data:
- Video footage of customer/employee interactions with the machine
- Device dimensions before usage
- Device dimensions after usage
- Thermal camera data
- Vibration sensor data
- Log (event) streams
The data collected from these streams will be routed through individual processors and filters for feature extraction and engineering before being passed into the model.
Preprocessing Modules and Their Feature Outputs:
- Video Processor
Extracts key frames where the customer or employee interacts with the machine. The video is further compressed or downsampled (e.g., from 24 FPS to 12 FPS) to reduce token count while retaining essential context for the VLM model. This processed video is then encoded for downstream use. - Dimension Analysis
A machine learning model estimates the device dimensions. Dimensions captured before interaction are stored as pre_interaction_dimension, and those after interaction as post_interaction_dimension and original_dimensions. A discrepancy between the two may indicate physical deformation or damage. - Event Stream Processor
System logs collected through a Remote Monitoring Agent are processed using a supervised learning model trained to detect anomalies. Changes in these logs, correlated with known damage events, can signal physical harm to the system. - Thermal Image Processor
This module runs periodically, capturing heat signatures and identifying hotspots on the device. By comparing thermal data against predefined thresholds for each hotspot, it raises alerts for potential issues. This module is not real-time, as temperature changes may not coincide precisely with the moment of physical damage, but it is useful for failure prediction. - Vibration Processor
Similar to the thermal processor, this module captures vibration data near the checkout machines and compares it to baseline vibration levels. Deviations from the norm trigger alerts. While it doesn’t pinpoint the cause or exact timing of damage, it supports proactive monitoring.
- Prompt Writer
In this module, we combine the outputs from various processors to generate a comprehensive prompt for querying the Vision-Language Model (VLM). The inputs include:
- Encoded video from the Video Processor
- Pre- and post-interaction dimensions from the Dimension Processor, including the original dimensions and the calculated delta
- Feature vectors or alerts from the Event Stream Processor
These elements are synthesized into a structured prompt that captures both the physical and contextual aspects of the system interaction. Various prompting techniques can be applied to optimize performance, including Zero-Shot Learning, Few-Shot Learning, and Chain-of-Thought Prompting.
The final output of this module is a fully formed prompt, ready to be fed into the VLM for classification or further analysis.
- LLM Model
This module utilizes a multimodal Generative AI model to process the input prompt and classify whether physical damage has occurred. The model interprets the combined features derived from video, dimensions, and system logs to make an informed decision. Depending on the use case and infrastructure requirements, either open-source solutions or closed-source models can be employed for this task.
Final Pipeline:
After preprocessing, features from all streams are combined into a unified prompt and fed into a VLM or LLM-based classifier. The model categorizes the interaction, determining whether physical damage has occurred. If damage is detected, the system generates an alert or incident report for repair actions. Additionally, the system can highlight the specific video frames during which the damage likely occurred, improving traceability and incident review.
We propose running the vibration-based data stream and the thermal image-based data stream independently. If anomalies are detected through either stream, the system can invoke the same module to generate an alert or create an incident report.
TGCS Reference 00182


